
“The most important thing in managing your AWS spend, is paying attention.”
Alex Lawn, Director and a founding member of Team Cloud at Catalyst.
A few years ago, we spent a lot of effort reducing our AWS spend as much as possible. Since then, we have been continually analysing, experimenting and applying innovative approaches in getting the most out of our AWS infrastructure, passing on as much of those savings onto our clients as we can.
Back in 2017, we shared with you some of the strategies we have used to cut our AWS spend in half (Read here) – all that is still relevant today and we recommend you have a browse to ensure you’re implementing that for your organisation.
Since then, we have identified some of the other areas in the cloud that could save us and our clients time and money, and we’d like to share some of them with you today.
AWS Budgets
AWS Budgets is a cost management tool that helps AWS customers monitor and control their spending on AWS services. Introduced in 2016, AWS Budgets enabled us to set alerts when various parts of our infrastructure exceed preset limits. We have configured email alerts at the account level, service level, for reserved instance coverage and utilisation, and some very targeted alerts for areas of infrastructure that have had problems. AWS Budgets is a free service that has been vital at keeping our spending under control while also helping identify areas for further optimisation.
Here is an example daily budget, showing a slow increase in usage of service, prompting a review in around 10th of April where issues were found and the budget was increased.
About 10 days later, you can see that something went wrong, causing unnecessary AWS spend.
Having received an email alert, the team planned corrective action and in just a few days were able to return the infrastructure to normal. Without an AWS Budget alert this increased infrastructure cost could have quickly got out of control, wasting thousands of dollars.
Reserved Instances and Saving Plans
In our previous blog on this topic, one of the cost savings tools mentioned was to utilise reserved instances to pay upfront for infrastructure in return for a discounted average rate. Catalyst still use reserved instances for Databases, Elastic Cache and open search. However, we have fully switched to Savings Plans for our reserved compute instance needs. This allows us to be much more flexible in the type of instances that we use.
Instance types
AWS now offers several hundred different instance types with different hourly rates. There are advantages and disadvantages to all of them.
As a general rule, we have stopped using all the older T2, M3, M1 instance types everywhere. These all have more modern faster and cheaper instance types with no downsides.
For all new infrastructure we have switched to using ARM based Graviton based instances. These machines from the T4g and M6g families are proving cost effective and better performing when compared to the T3 and M6 Intel based instances.
At Catalyst we have also completed switching to the R6G Graviton based RDS instances for additional database savings and performance, and we are looking forward to the R7G Graviton 3 based instances making their way to RDS.
Dynamic EBS
For our Webserver hosts, initially you need to allocate enough disk space to the Webserver AMI’s so that you never run out on any of the hosts for the life of the instances.
Then, you have to monitor all the machines in the Autoscale groups to make sure you don’t run out of space and take action to fix any disk space problems.
Running out of disk space can mean errors presented back to end users or data corruption issues.
AWS has long had the capability to expand EBS volumes in place at most once every six hours. At Catalyst, we have taken advantage of that and also use ephemeral instanced based storage https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html if available on the host which essentially allows a web-server host to grow it’s own disk by doing the following:
1) Start with a small 1GB LVM Physical volume with a logical volume mounted to /docker.
2) Provision any instance storage into Physical volumes for LVM.
3) In the event that low disk space is detected on the host we either allocate more space via LVM, grow an existing EBS volume or, if no volumes can be expanded due to the six hour limit or size constraints, allocate a new volume.
The end results are:
- EC2 Hosts can grow their disk and never run out
- No Over-provisioning of Disk to account for usage spikes on one of the hosts
- Can take advantage of faster, cheaper, instance based storage if available
This has been so successful for ECS hosts based on Amazon linux ECS optimised AMIs, we have been able to shrink the size from 30GB down to 5GB and rely on the auto expanding disk mechanics.
Overall, this has been a huge win in terms of AWS cost savings, and had the unexpected benefit of eliminating all pager events related to disk space for our web-servers.
Cross Availability Zone Traffic
In our original blog on this topic, we also talked about routing traffic to the local Gluster node wherever possible to keep traffic in the same availability zone. Our team at Catalyst have taken that another two steps forward:
Moodle cache traffic
By using some smart Redis traffic routing, we can keep all of our Redis read traffic fast and free by routing to a Redis read endpoint in the same availability zone, while allowing for cache writes to propagate to all three availability zones. This change has cut our cross AZ traffic related to Redis caching by 95%!
Database traffic
At Catalyst, we use AWS Aurora read replicas for approximately 75% of our database traffic. We have also developed a bunch of smart SQL routing that is Availability Zone aware. By utilising Aurora read replicas in the same availability zone as a web server, whenever capacity allows, we can cut our cross AZ traffic by around 50%.
Given a standard Moodle page might make around 50 database calls and a similar number of Redis calls, shaving 1-2ms off each network round trip, by keeping the traffic in the same Availability Zone, means we can shave 100-200ms of each page load. So while we save money on AWS, we also make your site faster.
Database optimisation
There are two major components to our AWS RDS spend:
The first is the RDS instances themselves, which we manage through a combination of selecting the optimal instance size and type, reserved instances and auto-scaling.
The second major component of our AWS spend is IO operations which can easily match our spend on the instances themselves.
Reducing the IO operations can be tricky. We do this by:
- Making the application smarter by trying to cache more query results and complex objects in Redis
- Making the queries simpler by modifying Moodle directly
- Adding indexes to our tables to avoid expensive full table scans
Some useful tools:
The AWS performance insights https://aws.amazon.com/rds/performance-insights/ has proven to be a valuable tool in helping us identify queries with high IOPS overhead. See below:
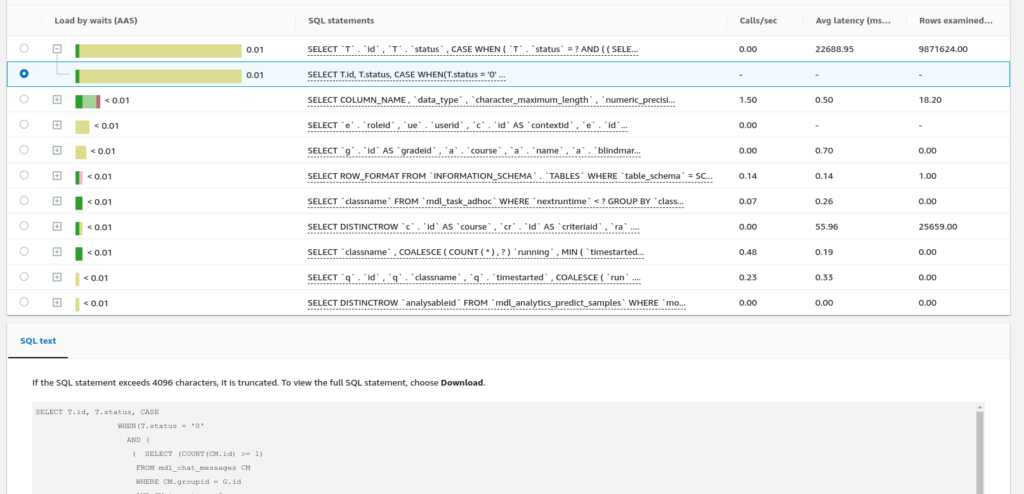
Here, performance insights has highlighted a potential query for investigation as it appears to take a long time to complete and examines 9.8 Million rows.
Excimer https://github.com/catalyst/moodle-tool_excimer is another great tool. Developed by Catalyst, Excimer is a sampling profiler for Moodle that has proven very useful in identifying Moodle performance problems, fixing of which often leads to AWS cost savings.
Here are a few of the core Moodle trackers that have benefited from our optimisation work:
https://tracker.moodle.org/browse/MDL-75435
https://tracker.moodle.org/browse/MDL-68164
https://tracker.moodle.org/browse/MDL-41439
https://tracker.moodle.org/browse/MDL-39571
S3 Life Cycle Policies
At Catalyst, we store several thousand Terabytes of data in S3. This includes: live Moodle application data, backup of databases, historical archives and other data.
Over the years, we have been optimising life cycle policies to move data to cheaper s3 tiers, taking advantage of S3 Intelligent tiering, or even outright deleting data that’s no longer necessary.
We now have a sophisticated suite of tags on our s3 buckets, and objects stored within them, we can report on. A combination of billing and other ad hoc reports alert us to any problems with s3 storage costs, and new buckets that need our attention.
Lightsail
Frequently, clients will ask Catalyst for a sandbox or demo environment that does not need any of the bells and whistles we normally offer in terms of performance availability and scalability.
To accommodate these bespoke sandbox sites we will spin up a Lightsail https://aws.amazon.com/lightsail/ self contained demo site. Lightsail is incredibly cost effective, and allows us to offer a level of access not normally available to our immutable auto scaling sites. This allows our new and existing clients to freely explore Moodle, add plugins and customise content – getting a full experience before making further decisions.
In summary, paying attention at all times is still the best strategy when it comes to managing your AWS spend. Getting knowledgeable people in a room to help you review your total spend and strategies is another. Engaging an AWS Partner to review your infrastructure usage will be a good investment for your business.
For more useful tips and latest industry news, follow us on LinkedIn or sign up to our Newsletter.
Would you like to use our highly optimised cloud infrastructure for your LMS or CMS?
You may also like:
Why Cloud Migrations Fail (LinkedIn Article by Catalyst IT Australia)
Optimise Performance of Your Moodle Site – thanks, Catalyst.
Does your digital strategy empower or hinder your business goals?
NEW! SCORM Wrapper (scormremote) plugin – easily connect your enterprise Moodle LMS with other LMS.


